What is AI Malware filtering?
Our traditional malware filter utilizes multiple source lists that are updated on an hourly basis. These lists are meticulously compiled from a variety of sources and threat intelligence feeds, which are then curated by us to remove false positives.
While this has served us and our customers well, we’re always looking for new tools to improve the value of our products. We decided to see if we can do better than the reactionary approach of curated lists by detecting malware domains *before* they ever appear in our malware blocklist.
Enter predictive malware detection and filtering.
Using machine learning algorithms, we built a model for detecting and blocking domains that have a high probability of serving malware. Considering the limited data that DNS queries alone provide, this was quite tricky, but here are the results we’ve been able to achieve.
Results and Benefits For Our Customers
TLDR; Block malware before it appears on a malware blocklist
The following demonstrates the effectiveness of our malware detection algorithm. We took new unseen domains from our existing malware blocklist, as well as a list of 1000 random benign domains from Alexa’s top 10,000 most popular websites, to determine the probability of a domain serving malware.
| Malware Probability | False Negative Rate | False Positive Rate |
|---|---|---|
| >50% | 20% | 20.98% |
| >60% | 16.68% | 16.14% |
| >70% | 11.44% | 12.28% |
| >80% | 8.45% | 8.34% |
| >90% | 4.06% | 4.49% |
A malware probability of greater than 50% implies the machine learning model predicts that a specific domain has a better than random chance of serving malware. If you were to block domains based on this probability, there would be roughly a 20% false positive and false negative rate. Considering that these are domains our traditional filter would have missed entirely (until the next hourly update), these results are not bad. Setting the AI filter to block domains with a probability of 80% or higher yields an accuracy of over 90%.
To enable this feature, head over to Profiles, then click on the “Edit” button for the desired Profile, then click Profile Options and then simply toggle it on.
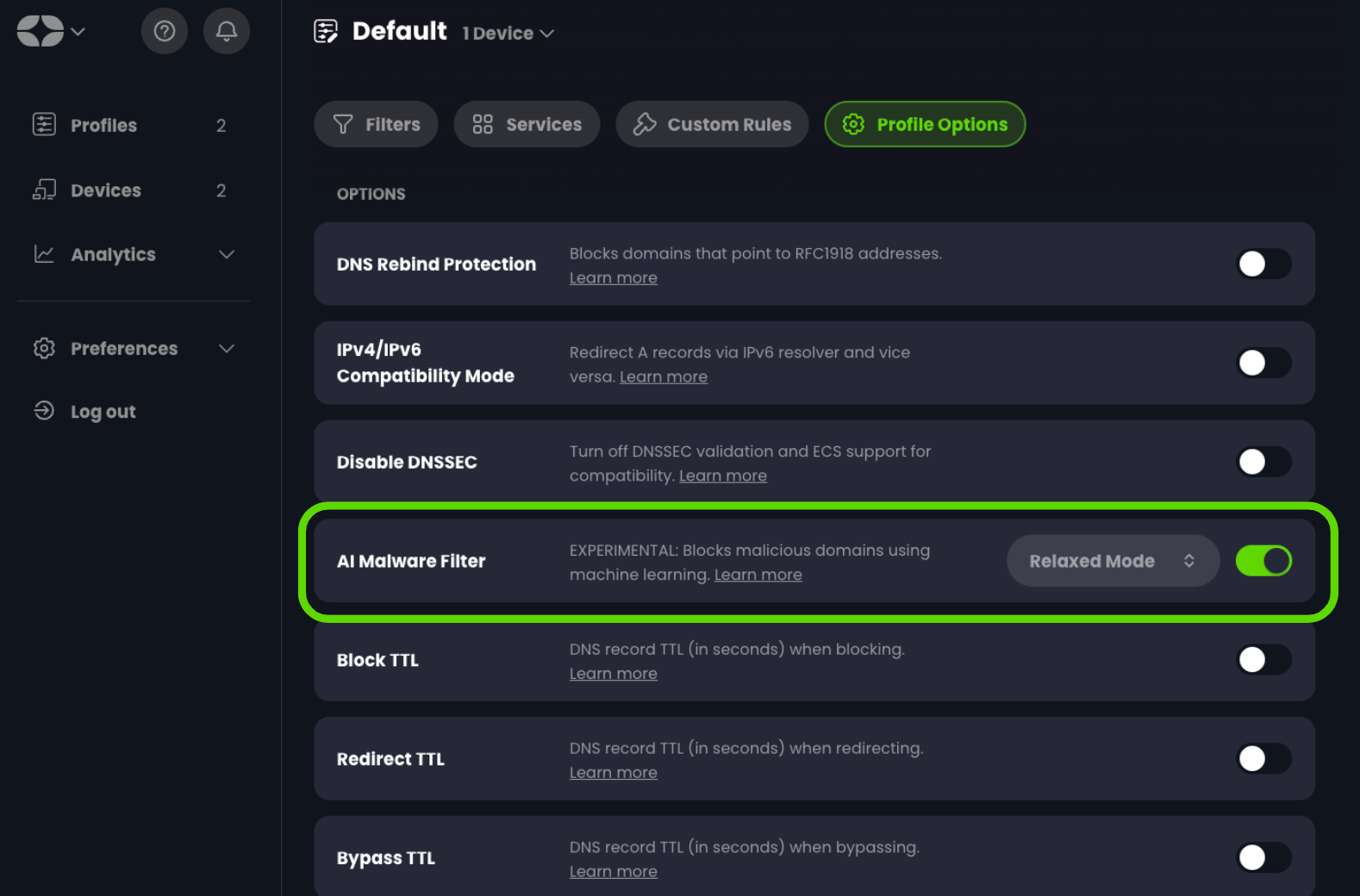
While this is by no means the end of the story for this feature, we are pleased to offer it to you now so that you can make your internet experience even safer and more secure.
For anyone who enjoys geeking out over the technical aspects of this project, the rest of this article will deep dive into the juicy details.
Development Lifecycle
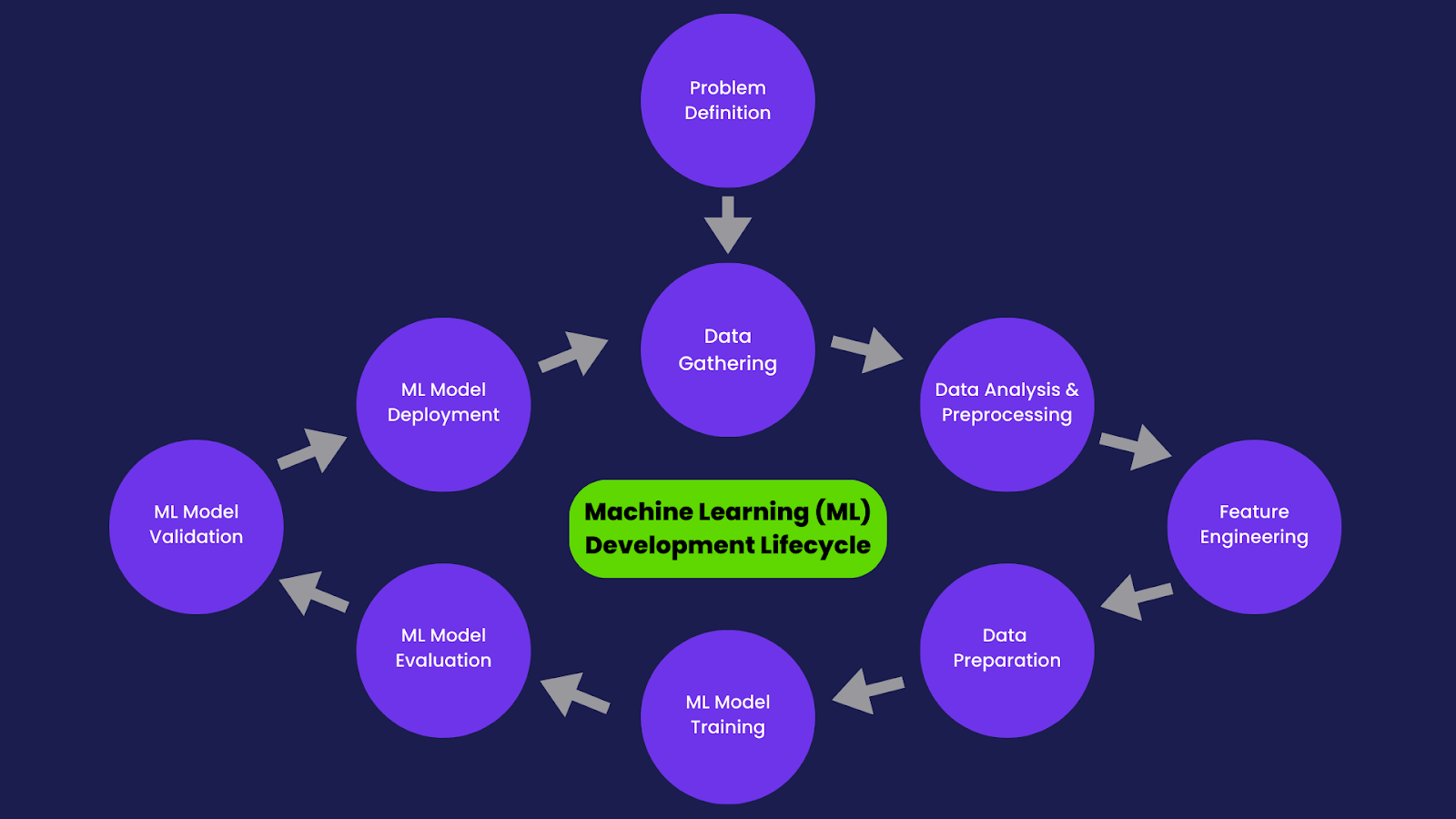
Data Gathering, Analysis, Feature Engineering & Data Preparation
Since our goal was to make accurate predictions about the probability of a domain serving malware, we needed to gather as much data about the domains we know to be serving malware. We started with our conventional malware blocklist, which provides us with a baseline dataset of roughly ~250,000 known malware domains.
To get as much signal from our data as possible, we identified a set of features we could extract from the details of a DNS request.
| Feature Name | Feature Type | Feature Description |
|---|---|---|
| Subdomain | Lexical | Subdomains |
| SLD | Lexical | Second Level Domain |
| TLD | Lexical | Top Level Domain |
| Domain_Len | Lexical | Domain Length |
| Subdomain_Len | Lexical | Subdomain Length |
| Count_Subdomain_Len | Lexical | Count of subdomain levels |
| Hyphen_In_Domain | Lexical | Contains Hyphen |
| Longest_Word_Ratio | Lexical | Longest word in domain ratio |
| Numeric_len | Lexical | Numeric count in domain |
| Char_Occ | Lexical | Character distribution |
| Domain_Entropy | Lexical | Domain Entropy (calculates the |
| Shannon entry of the string) | ||
| Unigrams | Lexical | Unigrams of the domain in |
| letter level | ||
| Bigrams | Lexical | Bigrams of the domain in |
| letter level | ||
| Trigrams | Lexical | Trigrams of the domain in |
| letter level | ||
| Domain | Lexical | DNS name |
| Domain_age | Third_Party | When was the domainr registered |
| IP | Third_Party | Internet Protocol |
| City Code | Third_Party | City Code |
| City | Third_Party | City Name |
| Country | Third_Party | Country Name |
| Latitude | Third_Party | Location Latitude |
| Longitude | Third_Party | Location Longitude |
| State/Province | Third_Party | State/Province Name |
| AS | Third_Party | Automated System Name |
| ISP | Third_Party | Internet Service Protocol |
| Organization | Third_Party | Name of the Organization |
- Feature selection was heavily inspired by this paper from 2021 on “Classifying Malicious Domains using DNS TrafficAnalysis”
We expanded the base dataset of just domain names into a database of each domain along with each feature. The “Third Party” data was looked up via geo-ip and whois databases.
Since machine learning can be considered highly specialized statistical models, we need to normalize the data into numerical formats that allow for mathematical operations. This is achieved using type conversion and encoding techniques like label encoding and one hot encoding.
Model Training & Evaluation
Now that we have both a known malware dataset and a benign dataset (top 100,000 Alexa websites), we are working with pre-labeled data. This means we can use a supervised learning algorithm to train our model. There are lots of algorithms to choose from, and after some review, we chose the XGBoost library, which is an implementation of Extreme Gradient Boosting.
When training a model, there are settings that will determine the way the model learns. These settings are called hyperparameters and must be tuned to the dataset. To determine these values, we performed hyperparameter tuning using grid search and random search on some of the crucial parameters of the XGBoost model, then re-trained with the best hyperparameter scores.
To evaluate the effectiveness of our model after training, we ran a portion of both the malware and benign datasets that the model had not seen during training, and reviewed a Confusion Matrix.
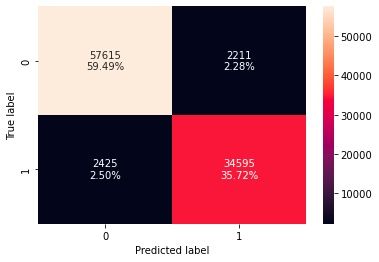
As we fine-tune the model to improve accuracy and reduce false positives, we need to have model explainability to understand what happens in the model from input to output.
For this, we use feature importance and SHAP Explainer. These methods help us understand the score for all of the input features and increase the interpretability of our models.
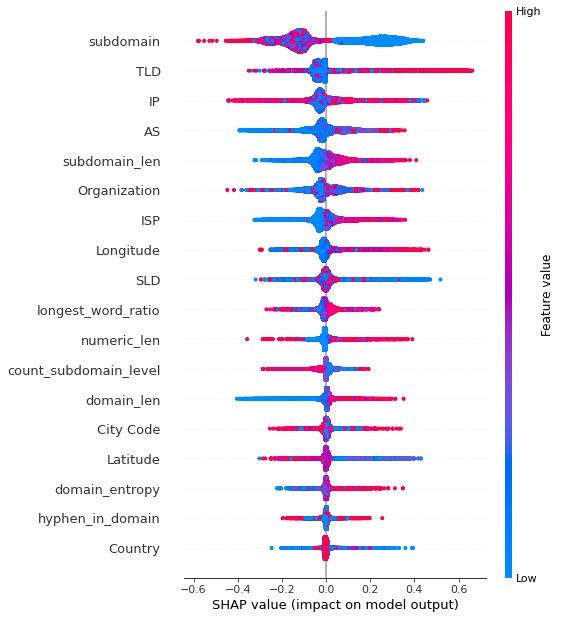
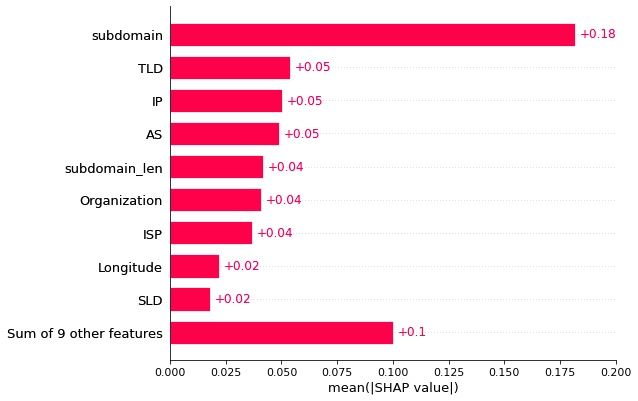
- Please note: the images in this post do not represent the state of the production model, as they were taken during initial development.
Initial Results
After tuning the features, we took a dataset of unseen malware domains that have appeared in our conventional malware blocklist. On this 1049 domain dataset, we achieved 93.9% accuracy.
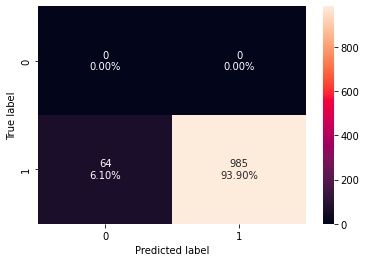
This accuracy comes at the cost of a fairly high false positive rate of over 20%. While this could be easily mitigated by implementing an allow-list of the most popular domains, the real show-stopping result was the prediction latency of ~100ms. We work very hard to keep DNS latency as low as possible for our users, and a 100ms addition to the existing latency would likely discourage even the most security-minded customers from using this feature.
Production Performance
To improve the prediction latency of the model, we explored various hardware and software optimization techniques. While we could get faster predictions using GPU computing, we needed to keep the inference in line with the incoming DNS request. However, running this model on a remote GPU would increase the cost and add additional latency due to the network latency between our DNS servers and the remote GPU instances.
Our only remaining option was to find software optimizations that can speed up the CPU-based computing available on our DNS servers.
After multiple failed experiments with Intel’s oneDAL, we settled on Microsoft's Hummingbird library. It is an excellent library that transforms machine-learning models into tensor computations. Using Hummingbird, we converted the existing model without modifying any inference code.
With the updated model, the prediction latency was reduced from 100ms to 10ms. That was a big win, with the only downside of a slightly increased false positive rate.
This increased false positive rate was easily mitigated by both an allow list for popular domains and a modification to the model that changes the output to a probability value from 0% to 100%, effectively allowing users to set the aggressiveness of the filter to fit their risk tolerance and user experience.
A New Component to a Comprehensive Security Strategy
Our new filter is a powerful tool for blocking malware. By leveraging the capability of machine learning and automation, our system can block threats in real-time, minimizing the chance of your network being compromised.
As with all of our new features, we would love to get your feedback so that we can improve our offerings, and continue to build more tools to improve your internet experience. You can reach out to us here:
Contact Us: https://controld.com/contact/
Feedback Portal: https://feedback.controld.com/
Discord: https://discord.com/invite/dns
Reddit: https://www.reddit.com/r/ControlD/
Future Development
While this was our first foray into the world of adding machine learning tools into our products, it will most certainly not be our last. We are already experimenting with new approaches to identifying network threats, as well as creating dynamic website categorization for much more robust filter and services capabilities and much more!